
计算机基础知识
1.练习地址
2.大纲要求
人工智能与大数据基础
一、容器集群的部署、配置与维护及容器技术的工作原理
二、分布式文件系统的基本概念、特点、管理与维护
三、图数据库的基本概念、数据模型及基本操作
四、机器学习算法的分类与应用
五、深度学习的基本概念、特点及应用
学习路径
一、容器集群(Docker、Kubernetes)
容器技术原理:基于操作系统层虚拟化(namespace、cgroups)。
特点:轻量级、快速启动、可移植。
集群工具:Kubernetes(K8s)。
K8s 功能:容器编排、负载均衡、自动扩缩容、服务发现。
👉 考点:容器 vs 虚拟机区别;K8s 的核心组件(Pod、Node、Master、Scheduler)。
二、分布式文件系统(HDFS 为典型)
基本概念:把大文件切分到多台机器存储,统一对外提供访问。
特点:高容错(多副本)、高扩展(节点可横向扩展)、适合大数据分析。
组成:NameNode(管理元数据)、DataNode(存数据)。
👉 考点:HDFS 三大特点;NameNode 作用;为什么适合大文件而不适合小文件。
三、图数据库(Neo4j)
概念:用 图结构(点+边+属性) 存储和查询数据。
数据模型:节点(实体)、边(关系)、属性(特征)。
特点:关系存储天然高效,适合社交、推荐、知识图谱。
常用语言:Cypher。
👉 考点:图数据库 vs 关系型数据库;图数据库应用场景。
四、机器学习(ML)
分类:
监督学习(有标签,例:分类、回归)
无监督学习(无标签,例:聚类、降维)
强化学习(奖励机制,例:游戏AI、自动驾驶)
常见算法:决策树、支持向量机(SVM)、KNN、聚类(K-means)。
👉 考点:监督/无监督区别;常见算法和应用。
五、深度学习(DL)
基本概念:基于神经网络的机器学习方法。
特点:多层特征提取、对大规模数据效果好。
典型模型:
CNN(图像识别)
RNN(序列数据,如语音、文本)
Transformer(NLP 主流架构)
应用:图像识别、语音识别、自然语言处理、自动驾驶。
👉 考点:深度学习 vs 传统机器学习;CNN/RNN 应用场景。
3.容器集群
选择题/填空题高频考点:
核心概念:镜像(Image)、容器(Container)、仓库(Registry)的定义与区别。
Docker特点:轻量级、秒级启动、隔离性、一致性(开发-测试-生产环境一致)。
核心原理:
Namespace:实现隔离(进程、网络、文件系统等)。PID Namespace、Net Namespace、 Mount Namespace、 UTS Namespace、 IPC Namespace 、 User Namespace。
Cgroups:实现资源限制(CPU、内存、磁盘I/O等)。
Union File System (联合文件系统):实现镜像的分层与复用。
Kubernetes (K8s) 核心组件与概念:
Pod:K8s最小部署和管理单元,一个Pod包含一个或多个容器。
核心组件:API Server、Scheduler、Controller Manager、etcd、kubelet的作用。
网络:Service的作用(服务发现和负载均衡)、Ingress的作用(管理外部访问)。
核心命令:kubectl get pods, kubectl apply -f <file.yaml>。
kubeadm快速部署k8s
监控:ELK Prometheus + Grafana
故障排查:熟练使用 kubectl get, kubectl describe, kubectl logs, kubectl exec 等命令来查看集群状态和诊断问题。
简答题可能题型:
简述Docker容器与虚拟机的区别。
答: Docker容器共享主机操作系统内核,无需 Guest OS,因此更轻量、启动更快、资源占用更少;虚拟机每个实例都包含完整的 Guest OS,通过 Hypervisor 与硬件交互,更加隔离但也更重。
简述Kubernetes中Pod和Service的关系。
答: Pod是动态创建和销毁的实体。Service作为一个稳定的抽象层,定义了一组Pod的访问策略(通过标签选择器Label Selector匹配Pod),为它们提供一个统一的访问入口(ClusterIP等)和负载均衡,解决了Pod IP不固定的问题。
说明Docker镜像的分层结构及其好处。
答: Docker镜像是只读的,由一系列分层文件系统叠加而成。好处是:共享资源(多个镜像可共享相同的基础层)、存储高效(镜像上传下载只需传输变化的部分)、加速构建(构建新镜像时,已存在的层可直接使用缓存)。
4.分布式文件系统
一、基本概念
分布式文件系统 是一种允许通过网络在多台计算机(节点)上共享文件和存储资源的软件系统。对用户和应用程序来说,它呈现为一个统一的文件系统视图,就像访问本地磁盘一样,但实际上文件被透明地存储在多台服务器上。
核心设计目标:将物理上分散的存储资源聚合起来,提供一个逻辑上统一、易于管理、高性能且高可靠的文件存储服务。
关键角色:
客户端:访问文件系统的应用程序或用户。
元数据服务器:管理文件系统的元数据(如文件名、目录结构、文件大小、权限、文件块的位置等)。它是整个系统的“大脑”。
数据服务器:实际存储文件数据块的服务器节点。文件通常被分割成固定大小的块(Chunk/Block),并以多副本的形式存储在不同的数据服务器上以实现容错。
二、常见分布式文件系统举例
HDFS:为大数据(Hadoop)生态设计的DFS,擅长一次写入、多次读取的场景。
Ceph:一个统一的分布式存储系统,不仅提供文件存储(CephFS),还提供对象和块存储,设计非常优雅和强大。
GlusterFS:一个无元数据服务器的DFS,通过弹性哈希算法定位文件,扩展性强。
Google GFS:是很多DFS的设计灵感来源,但不开源。
阿里云 PFS、腾讯云 CFS 等:云厂商提供的托管式DFS服务,简化了管理和维护工作。
三、主要特点
分布式文件系统的特点可以归纳为以下几个核心方面:
透明性
访问透明性:客户端像访问本地文件系统一样访问DFS,无需改变应用程序。
位置透明性:客户端无需关心文件的具体物理存储位置。
故障透明性:系统内部节点发生故障时,客户端可能只会感知到性能下降或短暂中断,但不会导致整体服务完全不可用。
可扩展性
容量扩展:可以通过简单地增加数据服务器节点来线性地扩展整个系统的存储容量。
性能扩展:可以通过增加服务器节点来提高整体的读写吞吐量。多个客户端可以并行访问不同的文件或同一文件的不同部分。
可靠性与可用性
数据冗余:通过副本机制(Replication),将同一数据块复制到多个不同的节点上。即使某个节点磁盘损坏,数据也不会丢失。
自动恢复:当检测到节点故障或数据副本丢失时,系统能自动从其他副本复制数据到新节点,恢复所需的副本数量。
高性能
并行访问:文件被分块存储,多个客户端可以同时读取一个文件的不同部分,极大地提高了大文件的读取速度。
负载均衡:请求可以被分发到不同的元数据和数据服务器上,避免单一节点成为性能瓶颈。
一致性
提供不同级别的一致性模型(如最终一致性、强一致性)。例如,保证一个客户端写入的数据能立即被其他客户端读到(强一致性),或者允许短暂的不一致但最终会一致(最终一致性)。
大数据的核心特征(4V):Volume(海量)、Velocity(高速)、Variety(多样)、Value(低价值密度)
HDFS 是 Hadoop 分布式文件系统,与 Hadoop 生态圈(MapReduce, Hive, HBase, Spark, Flink 等)是原生一体的。几乎所有大数据框架都原生优先支持 HDFS作为其默认存储层。
Apache Hadoop 是一种开源框架,用于高效存储和处理从 GB 级到 PB 级的大型数据集。利用 Hadoop,您可以将多台计算机组成集群以便更快地并行分析海量数据集,而不是使用一台大型计算机来存储和处理数据
Hadoop 的核心组成
HDFS(Hadoop Distributed File System,分布式文件系统)
用来存储超大规模数据。
把大文件拆分成数据块,分布到不同机器上。
每个数据块保存多个副本,提高容错性。
MapReduce(分布式计算模型)
一种编程模型,把任务分成 Map(映射) 和 Reduce(归约) 两步执行。
适合批处理大规模数据。
YARN(资源调度系统)
管理集群中的资源(CPU、内存等)。
负责任务调度和分配
📊 总结对比(类比记忆)
大数据架构图
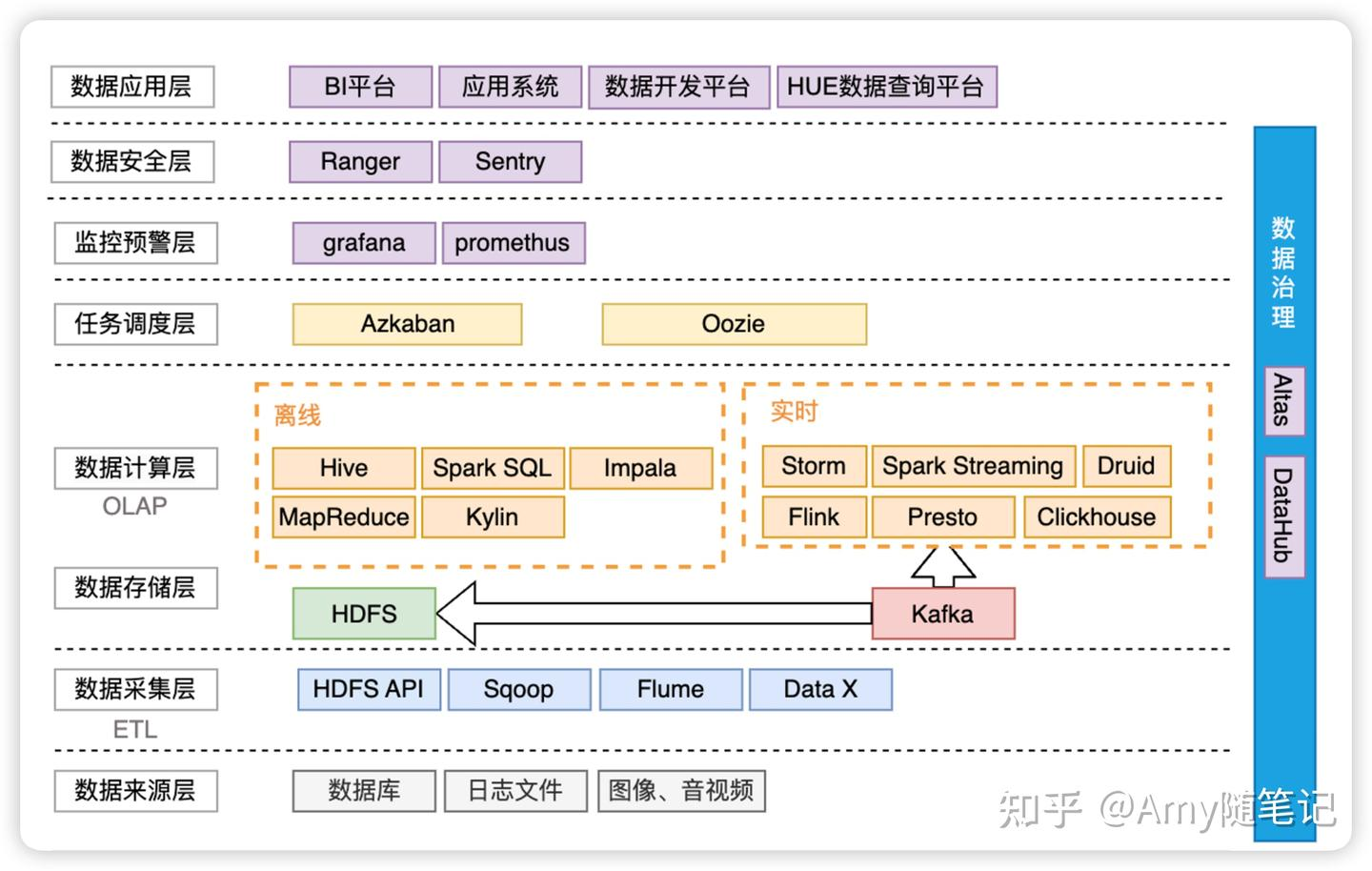
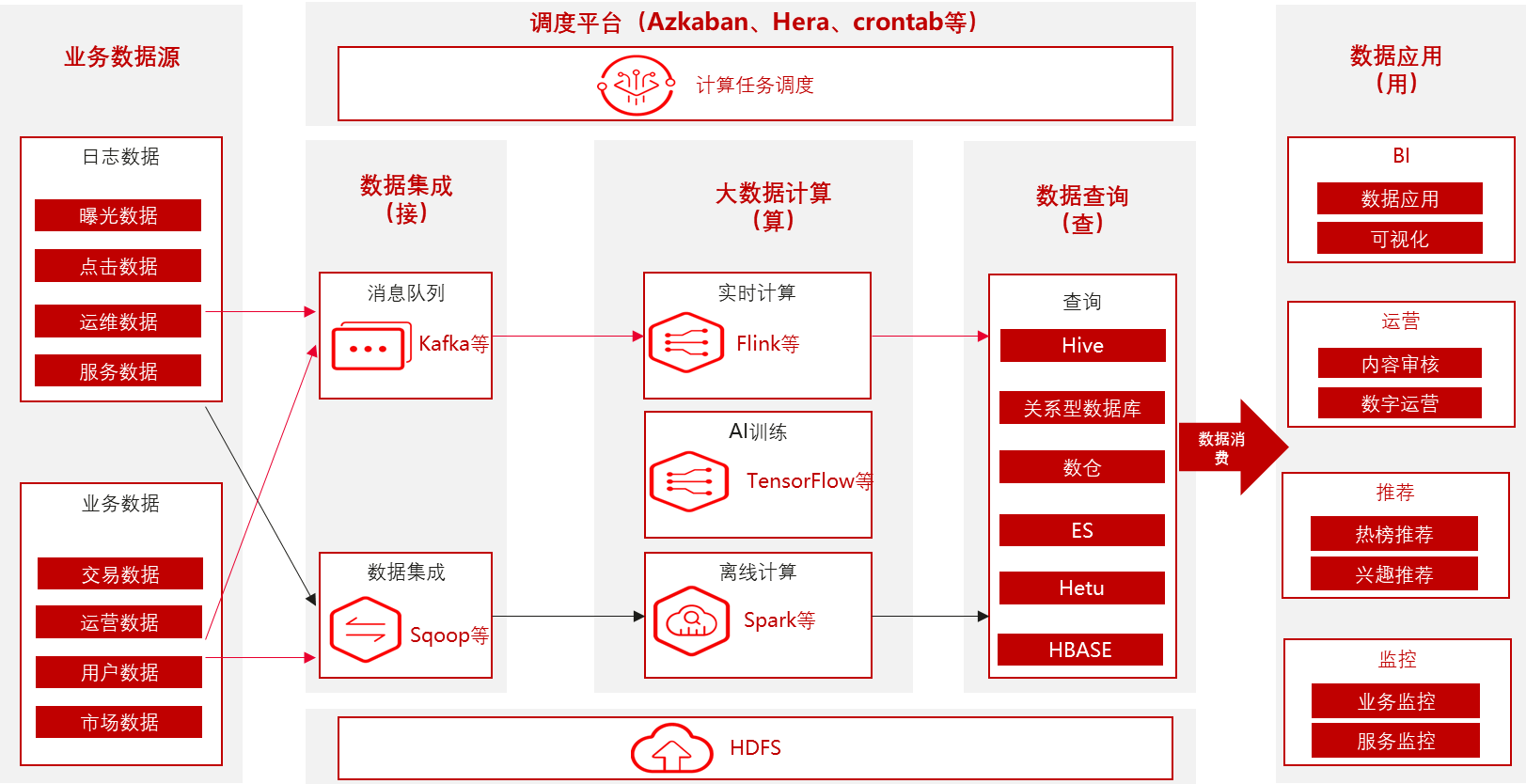
5.图数据库
图数据库(Graph Database)是用 点(Node)+ 边(Edge)+ 属性(Property) 来存储和表示数据关系的数据库,非常适合处理 关系复杂 的数据。
图数据库在人工智能中的作用:
常用于构建知识图谱、特征提取、图神经网络等,支持语义推理、智能搜索、关系挖掘,推动 AI 在推荐、搜索、医疗和自然语言处理等领域应用。
Neo4j
Neo4j 是一款高性能的 NoSQL 图数据库,它使用图(Graph)的结构来存储、管理和查询数据。其核心在于通过节点(Node)、关系(Relationship) 和属性(Property) 来直观地表示和处理复杂关联数据。
Neo4j 使用 Cypher 查询语言,语法类似 SQL,圆括号 () 表示节点;[] 表示边;{} 用来写属性
🧠 核心概念
理解 Neo4j,首先要掌握它的三个核心概念:
节点(Node):表示实体或对象,例如人、地点、产品等。节点可以有标签(Label) 对其进行分类(如
Person,Movie),并包含多个属性(Property)(键值对,如name: 'Alice')。关系(Relationship):表示节点之间的有向连接(如
FRIENDS_WITH,ACTED_IN)。关系是图数据库的灵魂,同样可以拥有属性(如since: 2023)。属性(Property):用于描述节点或关系的特征,以键值对的形式存在。
🔧 安装与配置
Neo4j 的安装比较简单,这里简要说明:
环境准备:确保系统已安装 JDK 11(Neo4j 官方推荐版本)。
下载安装:
桌面版 (Desktop):适用于桌面用户,提供图形化界面,方便管理和可视化。
社区服务器版 (Community Server):适用于服务器环境,通过命令行操作。
启动访问:安装完成后启动 Neo4j 服务,通过浏览器访问
http://localhost:7474,使用默认用户名neo4j和密码neo4j登录,之后需修改默认密码。
基本 Cypher 操作
Cypher 是 Neo4j 的声明式图查询语言,直观且强大。以下是一些最常用的操作:
💡 进阶技巧与运维
索引:为经常查询的属性创建索引可以大幅提升查询速度。例如
CREATE INDEX ON :Person(name)。自动化运维:对于生产环境,可以考虑使用 Docker 容器化部署、定期使用
neo4j-admin工具进行数据备份和恢复,并利用监控工具确保服务稳定。可视化工具:除了自带的 Neo4j Browser,还有许多第三方工具(如 Gephi)能提供更高级的图可视化分析功能。
🚀 典型应用场景
Neo4j 尤其擅长处理关系密集型场景:
社交网络:分析好友关系、发现社区、推荐可能认识的人。
推荐系统:基于共同喜好、关联内容进行精准推荐(“购买此商品的顾客也购买了...”)。
知识图谱:构建和查询复杂的实体关系网络,是搜索引擎和智能问答的基础。
金融风控:分析交易网络,识别欺诈团伙和异常模式。
供应链管理:追踪产品流程,优化路径,进行影响分析。
常用操作(Cypher)
(1)创建节点
CREATE (:Person {name:'Alice', age:25});
CREATE (:Movie {title:'Inception', year:2010});
(2)创建关系
MATCH (a:Person {name:'Alice'}), (m:Movie {title:'Inception'})
CREATE (a)-[:WATCHED {rating:5}]->(m);
解释:Alice 观看了 Inception,评分 5 分。
(3)查询节点
MATCH (p:Person) RETURN p;
(4)查询关系
MATCH (a:Person)-[r:WATCHED]->(m:Movie)
RETURN a.name, m.title, r.rating;
(5)条件查询
MATCH (p:Person)
WHERE p.age > 20
RETURN p.name, p.age;
(6)修改数据
MATCH (p:Person {name:'Alice'})
SET p.age = 26;
(7)删除数据
MATCH (p:Person {name:'Alice'}) DETACH DELETE p;
(DETACH 表示连同关系一起删除)
(8)路径查询(最短路径)
MATCH p = shortestPath((a:Person {name:'Alice'})-[:WATCHED*]-(b:Movie {title:'Inception'}))
RETURN p;1. 简述 Neo4j 的数据模型。
✅ 答案要点:
节点(Node):表示实体对象,如人、电影、商品。 ()
边(Relationship):表示节点间的联系,如“购买”、“朋友”。 []
属性(Property):为节点或关系提供额外信息。 {}
标签(Label):给节点分类,比如
:Person、:Movie。
2. Cypher 查询语言的基本语法特点是什么?
✅ 答案要点:
使用
()表示节点,[]表示关系。CREATE用于创建节点和关系。MATCH用于模式匹配和查询。WHERE用于条件过滤。必须用
DETACH DELETE才能删除节点和关系,否则报错类似 SQL,但更适合描述关系结构。
6.机器学习算法的分类与应用
要理解机器学习,最简单的方法是与我们熟悉的传统编程进行对比。
传统编程:我们编写明确的规则和指令,输入数据,让计算机遵循这些规则来生成答案。
模式:
数据 + 规则/程序 -> 答案例子:编写一个程序来识别垃圾邮件。你需要手动定义规则,比如“邮件中包含‘免费’、‘赢取’、‘现金’等关键词” -> 标记为垃圾邮件。这需要大量人力且难以覆盖所有情况。
机器学习:我们输入数据和对应的答案,让计算机自己找出背后的规则。一旦学会了这个规则,它就可以对新的数据给出答案。
模式:
数据 + 答案 -> 规则/模型例子:给计算机看一百万封已经被人为标记好“是垃圾邮件”或“不是垃圾邮件”的邮件。计算机通过分析这些样本,自己找出区分垃圾邮件和非垃圾邮件的“模式”(这些模式可能非常复杂,远超人类手动制定的规则)。之后,当你收到新邮件时,这个“学到的模式”就能自动判断它是不是垃圾邮件。
最主流和基础的分类方式是按照学习范式,主要分为以下四类:
1. 监督学习
核心思想:模型从已标注的训练数据中学习,即每个样本都包含输入数据及其对应的预期输出(标签)。模型的目标是学习一个从输入到输出的映射关系,以便对新的、未见过的数据做出准确预测。
关键概念:特征(输入变量)、标签(输出变量)。
主要任务:
分类:预测一个离散的类别标签。
例子:判断邮件是“垃圾邮件”还是“正常邮件”;判断肿瘤是“良性”还是“恶性”;识别图片中的动物是“猫”还是“狗”。
回归:预测一个连续的数值。
例子:预测明天的气温、预测房子的售价、预测公司的销售额。
2. 无监督学习
核心思想:模型从无标注的数据中学习,即只有输入数据,没有给定的输出标签。模型的目标是发现数据内部隐藏的固有模式、结构或分布。
主要任务:
聚类:将数据分成不同的组(簇),使得同一组内的数据点彼此相似,不同组的数据点不相似。
例子:客户细分(将客户分成不同的群体以便精准营销)、新闻主题分组、异常检测(与其他数据点截然不同的点可能就是异常点)。
降维:在尽量减少信息损失的前提下,将高维数据压缩到低维空间。目的是简化数据、减少计算开销、可视化(例如将数据降到2D或3D进行绘图)。
例子:可视化高维数据、图像压缩、预处理特征以提高后续模型的性能。
关联规则学习:发现数据中属性之间的有趣联系。
例子:购物篮分析(“买了尿布的顾客也经常会买啤酒”)。
3. 半监督学习
核心思想:介于监督学习和无监督学习之间。模型使用大量未标注数据和少量标注数据进行训练。这在现实世界中非常常见,因为获取大量标注数据的成本往往很高,而未标注数据则很容易获得。
例子:使用少量已标注的病毒图片和大量未标注的图片来训练一个更准确的医学图像识别模型。
4. 强化学习
核心思想:模型作为一个智能体,通过与环境进行交互来学习。智能体执行动作,环境会返回一个状态和奖励(正向或负向)。智能体的目标是学习一种策略,使得长期累积的奖励最大化。
关键概念:智能体、环境、状态、动作、奖励。
例子:
AlphaGo/AlphaZero:通过与自己下棋来学习最优策略。
自动驾驶:智能体(汽车)根据环境(路况)做出动作(转向、加速、刹车),好的驾驶行为获得正奖励,发生事故则获得负奖励。
机器人控制:学习如何行走、抓取物体。
监督学习是当前应用最广泛的范式,解决“预测”问题。
无监督学习是探索数据内在秘密的钥匙,解决“发现”问题。
强化学习是让AI在交互中学习决策的终极挑战,解决“决策”问题。
半监督学习则是一种实用主义的策略,巧妙利用大量廉价数据提升模型性能。
7.深度学习
核心思想:用“深度”神经网络学习“层次化”特征
您可以这样理解:
传统机器学习:需要人类专家来手动设计和提取数据的特征(例如,为了识别猫,我们需要告诉计算机“猫有尖耳朵、胡须、椭圆的眼睛”等特征)。这个过程叫特征工程,非常依赖人的经验和domain knowledge。
深度学习:我们不需要手动设计特征。我们只需要把原始数据(如图片的像素值)输入一个非常复杂的、多层的网络结构。这个网络会自动从数据中学习到越来越抽象、越来越复杂的层次化特征。
一个经典的图像识别例子:
假设我们要让机器识别一张图片里的“猫”。
第一层(底层):神经元只能看到一些局部的像素点,学习到非常简单的特征,比如边缘、角点、颜色。
中间层:接收下一层传来的简单特征(边缘和角点),并将它们组合成更复杂的特征,比如眼睛的轮廓、鼻子的形状、毛发的纹理。
最高层(输出层):接收下一层传来的复杂特征(眼睛、鼻子、毛发),并将它们组合成完整的、可识别的对象,比如“猫脸”、“狗脸”,最终给出判断结果。
这个过程就像拼乐高:最底层是积木块,中间层是用积木拼成的墙壁、窗户,最高层就是用这些部件拼成的完整城堡。
“深度” 这个词,就是指神经网络中拥有很多这样的中间层(又称“隐藏层”)。正是这些层数的“深度”,赋予了模型强大的表达能力。
深度学习的基础是人工神经网络,其灵感来源于人脑的神经元网络。
神经元:神经网络的基本单元。它接收输入信号,进行简单的加权求和并加上一个非线性变换(通过激活函数,如ReLU),然后产生一个输出信号。
简单比喻:像一个投票委员会,每个输入都有不同的权重(重要性),最后根据总票数(加权和)和一个规则(激活函数)做出决定(输出)。
神经网络:由大量神经元相互连接而成。神经元被组织成不同的层:
输入层:接收原始数据。
隐藏层:介于输入和输出层之间,进行特征提取和变换的层。深度就体现在这里,隐藏层可以多达上百甚至上千层。
输出层:输出最终的预测结果。
深度学习不是一个单一的算法,而是一个包含多种架构的家族,每种架构适合不同的任务:
核心特点
深度学习之所以强大,源于以下几个关键特点:
自动的特征工程
特点:无需人工手动设计和提取特征。模型直接从原始数据(如图像像素、文本字符)中自动学习到最有助于完成任务的特征表示。这是它与传统机器学习最根本的区别。
优势:解放了人力,并且机器发现的特征往往比人工设计的更丰富、更有效。
端到端学习
特点:建立一个单一的、统一的模型,从原始输入直接得到最终输出,所有优化目标都针对最终任务进行。
例子:一个端到端的语音识别系统,输入是音频波形,输出直接是文字。传统的系统可能需要先提取音素,再组合成词,再组句,每一步都是独立的模型,错误会累积。
强大的表示学习能力
特点:通过多层非线性变换,能够学习数据高度抽象的层次化特征表示。底层特征被组合成更复杂的高层特征。
例子:在图像识别中,从边缘 -> 纹理 -> 部件 -> 对象的分层学习过程。
对大规模数据和高性能计算的依赖
特点:深度学习模型通常有数百万甚至数十亿个参数,需要海量数据来训练,以避免过拟合。同时,训练过程涉及巨大的计算量,高度依赖GPU、TPU等专用硬件进行并行加速。
“黑盒”性质
特点:由于模型极其复杂,我们很难清晰理解模型内部具体是如何做出某个决策的。尽管有可解释性AI在研究,但其决策过程仍然不够透明。
挑战:在医疗、金融等需要决策解释的领域,这是一个不容忽视的问题。
主要应用领域
深度学习已经 revolutionized 了多个领域,以下是一些最成功的应用:
1. 计算机视觉
图像分类:识别图像中的主要对象(如ResNet识别千种物体)。
目标检测:不仅识别物体,还要定位出它在图像中的位置(如YOLO, Faster R-CNN用于自动驾驶中检测车辆、行人)。
图像分割:对图像中的每个像素进行分类(如医学图像中分割出肿瘤区域)。
图像生成:根据文本描述或另一张图像生成全新的、逼真的图像(如DALL-E, Midjourney, Stable Diffusion)。
2. 自然语言处理
机器翻译:谷歌翻译、百度翻译等背后的技术已全面转向深度学习(如Transformer模型)。
文本生成:写作助手、自动生成新闻摘要、以及像ChatGPT这样的对话式AI。
情感分析:分析一段文本的情感倾向(正面、负面、中性)。
语音识别:将语音转换为文字,如Siri、小爱同学、Alexa等语音助手。
3. 其他重要应用
推荐系统:Netflix、YouTube、淘宝的“猜你喜欢”背后都有深度学习的驱动,它能够挖掘用户和物品之间极其复杂的非线性关系。
游戏与机器人:通过强化学习(深度学习与强化学习的结合),AI智能体可以自学成才,达到超越人类的水平,如AlphaGo、AlphaStar。
生物信息学:蛋白质结构预测(如AlphaFold2)、新药研发、基因序列分析。
自动驾驶:感知周围环境(识别、检测)、决策规划(判断如何行驶)都深度依赖深度学习模型。